Contributing - Getting Started
The primary function of the service script is to acquire and scrape metadata information, as well as construct arrays of Tile URLs to be downloaded later.
These are the fundamental steps in integrating a service into sv_dlp.
It is strongly suggested to study the scripts of the pre-written services to
gain a comprehensive understanding of their functioning.
Required Classes/Functions
-
urlsUsed for building single URLs. Useful for loops._build_tile_url(pano_id, zoom=3, x=0, y=0)_build_metadata_url(pano_id=None, lat=None, lng=None, mode="pano/ll")_build_short_url(pano_id, heading=0, pitch=0, zoom=90))
-
miscMiscellaneous features, mostly for:get_pano_from_url(url)short_url(pano_id, heading=0, pitch=0, zoom=90))
Although cool to have, some services don't fully support it. If that is the case or want to implement it later,
raise sv_dlp.services.ServiceNotSupported. -
metadataget_metadata(pano_id=None, lat=None, lng=None, get_linked_panos=False)_parse_panorama(md, raw_md, output="")_get_raw_metadata(pano_id)_get_pano_from_coords(lat, lng)get_gen(metadata/image_size/etc)Obligatory to include; raiseraise sv_dlp.services.ServiceNotSupportedif metadata doesn't included info about gen.
Building Metadata
.urls._build_metadata_url.metadata.get_metadata.metadata.get_raw_metadata.get_pano_from_coords._parse_panorama(md, raw_md, output="")
sv_dlp's metadata structure is vastly dissimilar than the choosen service's raw_metadata; designed with compatibility in mind, it allows developers to tinker with the data no matter the service picked.
sv_dlp's metadata is returned as a MetadataStructure object, providing
the developer a more struictured and organized way to handle and
manipualte metadata information by the means of attributes.
An example of metadata in the form of a MetadataStructure object is:
metadata = MetadataStructure(
service=service,
pano_id=pano_id,
lat=lat,
lng=lng,
date=datetime.datetime(),
size=image_size,
max_zoom=max_zoom,
timeline=[{'pano_id': 'pano_id', 'date': datetime.datetime()}],
linked_panos={{'pano_id': pano_id, 'lat': lat, 'lng': lng, 'date': datetime.datetime()}},
misc={}
)
Additionally, the .dict() method returns the attributes of
each instance of the MetadataStructure class in the form of a
dictionary, allowing for easy access and manipulation of the
metadata information.
An example of sv_dlp's metadata in the form of a dictionary is the one below:
metadata = {
"service": service,
"pano_id": raw_md['pano_id']
"""
If raw metadata returns two key IDs (which are necessary for a download),
a list must be allocated inside of it like this:
"""
{
"pano_id": pano_id,
"image_id": image_id
}
"lat": raw_md['coordinates']['lat'],
"lng": raw_md['coordinates']['lng'],
"date": date # must be returned as a datetime object,
"size": [raw_md['image']['width'], raw_md['image']['height']],
"max_zoom": len(raw_md['image']['zooms']) - 1,
"misc": { # only use with exclusive service features
"gen": gen,
},
"timeline": {
[{'pano_id'}: pano_id, "date": date}],
[{'pano_id'}: pano_id, "date": date}],
[{'pano_id'}: pano_id, "date": date}],
# and so on...
}
"linked_panos": {
'''
Only if get_linked_panos is set to true
'''
[{'pano_id'}: pano_id, "date": date, "lat": lat, "lng" lng}],
[{'pano_id'}: pano_id, "date": date, "lat": lat, "lng" lng}],
[{'pano_id'}: pano_id, "date": date, "lat": lat, "lng" lng}],
# and so on...
},
}
In order to begin extracting the metadata, raw_metadata initiates a call to the
appropriate API obtained from urls._build_metadata_url. If coordinates are parsed,
get_pano_from_coords is first called to obtain the correct Panorama ID.
However, this may vary depending on the service being worked on; some services only get raw_metadata
from Panorama ID, while others with coordinates. To avoid any confusion, it is highly recommended
to raise sv_dlp.services.MetadataPanoIDParsed or sv_dlp.services.MetadataCoordsParsed.
If raw_metadata contains data related to timeline or linked_panos,
_parse_panorama can be used in a for in loop to correctly parse each panorama
within its respective segment (timeline or linked_panos).
Building array of Tiles URLs
.urls._build_tile_url.build_tile_arr
When metadata is parsed, sv_dlp executes the _build_tile_arr function, which creates an array
of all tiles based on the pano_id foudn in the given metadata; each tile is done individually using
the _build_tile_url function found in the urls class.
In the array, each column and row represents its x and y position respectfully on the panorama, such as the one shown below.
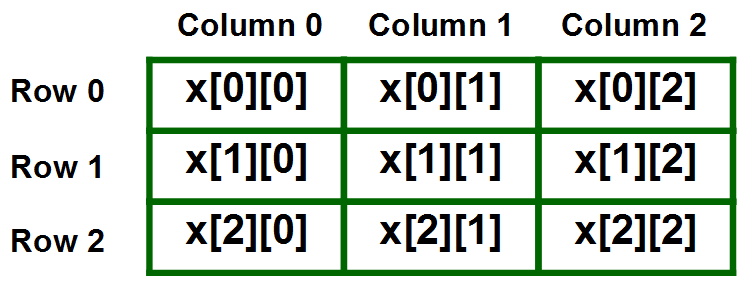
After building the array, a ThreadPoolExecutor (multi-threading) object is called; threads are generated
based on the length of the y axis; each thread downloads its respectful row and stores it
into a Tile IO array with its respectful axis position.
A big benefit of using multi-threading is time. If downloading a panorama with a lower zoom level difference isn't that much, but within my own testings downloading larger zoom levels take huge amounts of seconds (45s w/o multithreading -> 5s w/ multithreading).
Once the downloading process is complete, all rows get stitched separately then all columns are merged into one single image.
Post-Scrapping
After obtaining the metadata & building the array of Tile URLs sv-dlp will take
charge of the post-process, such as downloading or returning the data.
If you want to add/change something in the post-process, feel free to check
out sv_dlp.download.